пʼятницю, 29 липня 2011 р.
четвер, 28 липня 2011 р.
Огляд операційної системи Linux
Linux - вільно розповсюджуване ядро Unix-подібної системи, написане Лінусом Торвальдсом за допомогою великого числа добровольців по всій Мережі. Linux має усі властивості сучасної Unix-системи, включаючи дійсну багатозадачність, розвиту підсистему керування пам"яттю і мережеву підсистему. Ядро Linux, що поставляється разом із вільно розповсюджуваними прикладними і системними програмами утворить повно функціональну універсальну операційну систему. Велику частину базових системних компонентів Linux успадкував від проекту GNU, ціллю якого є створення вільної мікроядерной операційної системи з обличчям Unix. На сьогоднішній день існує множина різноманітних постачань Linux, дистрибутивів, що можна розділити на дистрибутиви загального призначення і спеціалізовані. До спеціалізованих дистрибутивів відносяться такі як Linux Router - урізане постачання Linux для створення дешевого маршрутизатора на базі старого PC та ін. Незважаючи на розходження в дистрибутивах загального призначення, усі вони утворять обличчя ОС Linux таким, яким їх знають більшість користувачів ОС. На відміну від ядра, дистрибутиви можуть містити комерційні компоненти і тому їхнє вільне поширення може бути обмежено. У такому випадку автори дистрибутивів роблять доступними усі вільні компоненти. Звичайно під словосполученням "ОС Linux" розуміють дистрибутиви Linux загального призначення.
Linux є високо масштабною системою, спроможною задовольнити інформаційні потреби на великих і малих підприємствах. При цьому обслуговування ОС Linux не ставить надмірних вимог до вашої кваліфікації.
ОС Linux перетворилась в операційну систему для бізнесу, освіти та індивідуального користування. Це багатозадачна, багатокористувацькою операційна система, тобто система, в якій одночасно можуть працювати декілька сотень користувачів і одночасно може бути запущено багато задач.
Як і будь–яка інша операційна система, Linux постійно вдосконалюється. Будь-який користувач може взяти участь в розробці операційної системи Linux та її вдосконаленню. Звичайно - ж при відповідній кваліфікації і відповідних навичках роботи з ОС Linux.
Оскільки Linux постійно розвивається, то вже існує багато версій ОС Linux.
1. RedHat Linux 5.1
2. Red Hat Linux release 5.2 (Apollo)
3. KSI Linux release 2.0 (Nostromo),
Як і ОС UNIX, операційна система Linux складається із чотирьох основних компонентів:
ядро,
shell,
файлова система,
утиліти.
Ключові риси LINUX.
Багатозадачна операційна система, захищеного 32-х розрядного режиму, у її складі немає 16-ти розрядного коду, крім підпрограми завантаження.
Передова 32[64 для Alpha] бітна підсистема віртуальної пам"яті.
Відсутнє обмеження 640к. LINUX може виділити до 3Гб на процес, якщо у вас є досить віртуальної пам"яті.
Система безпеки файлів і процесів користувача.
Мережна система графічного інтерфейсу “X Windows”, що відповідає промисловому стандартові. Запуск додатків через мережу. Можливість роботи додатків з багатьох машин на вашій робочій станції одночасно.
Загальні бібліотеки (“Shared libraries”) для підвищення ефективності використання пам"яті і дискового простору.
Прозора програмна емуляція мат. співпроцесора для машин без такого.
API стилю POSIX.1 з USL і BSD розширеннями. Перенос майже будь-якого коректно написаного Posix або Unix API додатка є тривіальною задачею.
Убудована підтримка мережі TCP/IP включаючи обидва протоколи і стандартний набір інструментів BSD.
Широкий спектр WWW інструментів.
Клієнт і сервер NFS - стандартної мережної файлової системи Unix.
SAMBA SMB сервер для LAN manager і клієнтів Windows for Workgroups.
MARS_NWE сервер клону Netware для використання в мережах IPX.
Netatalk Appletalk сервер для використання в мережах Appletalk.
Клієнт і сервер SMTP (E-mail) включаючи підтримку MIME.
Програмне забезпечення для UUCP - протоколу старого стилю для ефективного збереження і маршрутизації мережної інформації
Огляд можливостей Linux
Переносимість
Велика частина ядра Linux написана на мові С, завдяки чому система достатньо легко переноситься на різноманітні апаратні архітектури. Сьогодні офіційне ядро Linux працює на платформі Intel (починаючи з i386), Compaq (ex. Digital) Alpha, Motorolla 68k, MIPS, PowerPC, Sparc, Sparc64, StrongArm, Intel Italium (IA-64). Крім того, існує багато портів Linux, що поширюються окремо від офіційного ядра. Ядро Linux здатне працювати на багатопроцесорних SMP системах, забезпечуючи ефективне використання всіх процесорів. Підтримка архітектури NUMA знаходиться в стадії розробки. Розробники Linux намагаються дотримувати стандартів POSIX і Open Group, забезпечуючи тим самим переносимість ПЗ з іншими Unix-платформами.
Мережева підсистема
TCP/IP зтік у Linux відповідає усім стандартам і в багатьох можливостях перевершує реалізацію TCP/IP в інших ОС. Підтримка TCP/IP містить у собі просунуту маршрутизацію (policy routing, Qo and Fair Quering), traffic shaping, пакетну фільтрацію (firewalling), multicasting, підтримку "прозорого" проксі, masquerading, тунелінг, aliasing та ін. Крім IPv4, у ядро Linux входить експериментальна підтримка IPv6. Підтримується більшість існуючих мережевих пристроїв: Ethernet адаптерів (10/100Mbit, 1000Mbit, радіо карт), SLIP/PPP, FDDI, HIPPI, Frame Relay, Token Ring, WAN адаптери та ін. Linux містить підсистеми підтримки AX. 25 і ISDN.
Файлова система
Основною файловою системою Linux є його власна ext2fs. Офіційне ядро містить підтримку більш ніж 20 різноманітних файлових систем, включаючи FAT (FAT/VFAT/FAT32), ISO9660 (CD - ROM), HPFS (OS/2), NTFS (Windows NT), Sys (SCO Unix та ін.), UFS (BSD та ін.). У стадії розробки знаходяться файлові системи: ext3fs (кореспондуюча версія ext2fs), RaiserFS (швидка кореспондуюча файлова система). SGI і IBM займаються розробкою підтримки своїх кореспондуючих файлових систем XFS (з Irix) і JFS (з AIX) відповідно.
Прикладне ПЗ
Засоби розробки додатків
Більшість засобів розробки для Linux сьогодні були створені в рамках проекту GNU. Вони містять у собі GCC - Gnu Compiler Colection - універсальний переносний компілятор, GDB - Gnu Debuger - відлагоджувач, GNU C Library та ін. Компілятор GCC створювався максимально переносним, завдяки чому він підтримує біля 100 різноманітних апаратних платформ. Мова опису платформи добре документована, завдяки чому перенос GCC на нову архітектуру не складає особливої проблеми. "Зверху" GCC являє собою компілятор мов С (KR C, ANSI C, C9x і власні розширення), C++ (ANSI C++, STL), Objective C, Fortran 77, Effiel. Останні версії GCC містять також компілятор мови Java у машинно залежні коди. Окремо від GCC поширюються компілятори Ada95 і Pascal, що використовують gcc для генерації коду. Для Linux також існують інтерпретатори Lisp, Scheme і інших Lisp-подібних мов, скриптових мов Perl, AWK, Shell, Sed та ін. Існують засоби підтримки ведення проекту і контролю версій (CVS), група пакетів, що полегшують написання переносних програм: autoconf, automake, libtool та ін., різноманітні IDE.Компанія IBM перенесла на Linux своє середовище розробки Java додатків - IBM VisualAge for Java на Linux. Inprise (Borland
ПЗ для серверів Internet/Intranet
Стандартно в постачання Linux входять: Apache - самим популярний у Internet http-сервер, Sendmail - програма передачі електронної пошти (Mail Transfer Agent), ftp, pop3/imap, news сервери, сервер доменових імен, uucp over tcpip, squid ( кешируючий http/ftp проксі), засоби динамічної маршрутизації та ін.
Файл сервер
Linux може служити файл сервером по протоколах NFS (як правило використовуваному тільки на Unix машинах), SMB (Netbios over TCP/IP, використовуваний на різноманітних Windows платформах), AppleShare і IPX (Novell).
Middleware
Існує декілька вільних реалізацій архітектури OMG CORBA.
Графічний інтерфейс
Linux використовує стандартну віконну систему X. У більшості дистрибутивів використовується вільно розповсюджувана реалізація X"ів XFree86. - підтримує (майже) усі популярні графічні адаптери на платформі Intel та деякі інші. Віконна система X побудована на клієнт-серверній архітектурі, у такий спосіб місце запуску додатка і місце його відображення можуть бути фізично рознесені по мережі. У останню (поки експериментальну) версію XFree86 - 4.0, входить підтримка OpenGL і апаратної 3D акселерації.
Засоби розробки під X, що входять у стандарт, подають тільки базовий API розробника. Як правило при розробці додатків використовують додаткові бібліотеки для побудови інтерфейсу. Набір інтегрованих базових додатків, побудованих на одній бібліотеці утворить графічне середовище користувача. Найбільше популярні графічні середовища сьогодні - Gnome (GNU Network Object Model Environment) і напівкомерційне середовище KDE.
СКБД
Основні виробники систем керування базами даних вже перенесли свої продукти на Linux: існують Linux версії IBM DB2, Informix, Oracle, Sybase, Corel/Inprise Interbase та ін. Linux може використовуватися в якості платформи для запуску системи керування підприємством SAP R/3.
Засоби підготування текстів
У дистрибутивах Linux звичайно поставляється TeTeX реалізація TeX - системи верстки текстів топографічної якості, створеної американським математиком і програмістом Дональдом Кнутом. Система TeX та макропакет високого рівня LaTeX сьогодні використовуються для публікації наукових статей, часописів і книг.
SGML Tools: засоби трансформації структурованого по правилах SGML тексту в LaTeX, HTML, GNU info, LyX, RTF, plain text і інші формати з одного вихідного тексту, орієнтовані на створення технічної документації.
Офісні пакети
Крім декількох проектів по створенню вільно розповсюджуваного комплекту офісних додатків для X"ів, під Linux існують комерційні офіси SUN Staroffice (сьогодні абсолютно безкоштовний для будь-якого застосування), Corel WordPerfect, Applix Applixware та деякі інші.
Ігри
Виробники комп"ютерних ігор вже звернули свою увагу на Linux. Вже вийшли Linux версії Doom, Doom2, Heretic, Descent, Quake, Quake II, Quake III test, Unreal, Myth II, Civilisation III Ctp та ін. С виходом XFree86 4.0, що містить крім всього іншого орієнтовану на ігри підсистему швидкої графіки і OpenGL, очікується збільшення числа ігор під Linux. Linux може служити сервером для ігор QuakeWorld, QuakeII, QuakeIII test, Unreal та ін.
Linux є високо масштабною системою, спроможною задовольнити інформаційні потреби на великих і малих підприємствах. При цьому обслуговування ОС Linux не ставить надмірних вимог до вашої кваліфікації.
ОС Linux перетворилась в операційну систему для бізнесу, освіти та індивідуального користування. Це багатозадачна, багатокористувацькою операційна система, тобто система, в якій одночасно можуть працювати декілька сотень користувачів і одночасно може бути запущено багато задач.
Як і будь–яка інша операційна система, Linux постійно вдосконалюється. Будь-який користувач може взяти участь в розробці операційної системи Linux та її вдосконаленню. Звичайно - ж при відповідній кваліфікації і відповідних навичках роботи з ОС Linux.
Оскільки Linux постійно розвивається, то вже існує багато версій ОС Linux.
1. RedHat Linux 5.1
2. Red Hat Linux release 5.2 (Apollo)
3. KSI Linux release 2.0 (Nostromo),
Як і ОС UNIX, операційна система Linux складається із чотирьох основних компонентів:
ядро,
shell,
файлова система,
утиліти.
Ключові риси LINUX.
Багатозадачна операційна система, захищеного 32-х розрядного режиму, у її складі немає 16-ти розрядного коду, крім підпрограми завантаження.
Передова 32[64 для Alpha] бітна підсистема віртуальної пам"яті.
Відсутнє обмеження 640к. LINUX може виділити до 3Гб на процес, якщо у вас є досить віртуальної пам"яті.
Система безпеки файлів і процесів користувача.
Мережна система графічного інтерфейсу “X Windows”, що відповідає промисловому стандартові. Запуск додатків через мережу. Можливість роботи додатків з багатьох машин на вашій робочій станції одночасно.
Загальні бібліотеки (“Shared libraries”) для підвищення ефективності використання пам"яті і дискового простору.
Прозора програмна емуляція мат. співпроцесора для машин без такого.
API стилю POSIX.1 з USL і BSD розширеннями. Перенос майже будь-якого коректно написаного Posix або Unix API додатка є тривіальною задачею.
Убудована підтримка мережі TCP/IP включаючи обидва протоколи і стандартний набір інструментів BSD.
Широкий спектр WWW інструментів.
Клієнт і сервер NFS - стандартної мережної файлової системи Unix.
SAMBA SMB сервер для LAN manager і клієнтів Windows for Workgroups.
MARS_NWE сервер клону Netware для використання в мережах IPX.
Netatalk Appletalk сервер для використання в мережах Appletalk.
Клієнт і сервер SMTP (E-mail) включаючи підтримку MIME.
Програмне забезпечення для UUCP - протоколу старого стилю для ефективного збереження і маршрутизації мережної інформації
Огляд можливостей Linux
Переносимість
Велика частина ядра Linux написана на мові С, завдяки чому система достатньо легко переноситься на різноманітні апаратні архітектури. Сьогодні офіційне ядро Linux працює на платформі Intel (починаючи з i386), Compaq (ex. Digital) Alpha, Motorolla 68k, MIPS, PowerPC, Sparc, Sparc64, StrongArm, Intel Italium (IA-64). Крім того, існує багато портів Linux, що поширюються окремо від офіційного ядра. Ядро Linux здатне працювати на багатопроцесорних SMP системах, забезпечуючи ефективне використання всіх процесорів. Підтримка архітектури NUMA знаходиться в стадії розробки. Розробники Linux намагаються дотримувати стандартів POSIX і Open Group, забезпечуючи тим самим переносимість ПЗ з іншими Unix-платформами.
Мережева підсистема
TCP/IP зтік у Linux відповідає усім стандартам і в багатьох можливостях перевершує реалізацію TCP/IP в інших ОС. Підтримка TCP/IP містить у собі просунуту маршрутизацію (policy routing, Qo and Fair Quering), traffic shaping, пакетну фільтрацію (firewalling), multicasting, підтримку "прозорого" проксі, masquerading, тунелінг, aliasing та ін. Крім IPv4, у ядро Linux входить експериментальна підтримка IPv6. Підтримується більшість існуючих мережевих пристроїв: Ethernet адаптерів (10/100Mbit, 1000Mbit, радіо карт), SLIP/PPP, FDDI, HIPPI, Frame Relay, Token Ring, WAN адаптери та ін. Linux містить підсистеми підтримки AX. 25 і ISDN.
Файлова система
Основною файловою системою Linux є його власна ext2fs. Офіційне ядро містить підтримку більш ніж 20 різноманітних файлових систем, включаючи FAT (FAT/VFAT/FAT32), ISO9660 (CD - ROM), HPFS (OS/2), NTFS (Windows NT), Sys (SCO Unix та ін.), UFS (BSD та ін.). У стадії розробки знаходяться файлові системи: ext3fs (кореспондуюча версія ext2fs), RaiserFS (швидка кореспондуюча файлова система). SGI і IBM займаються розробкою підтримки своїх кореспондуючих файлових систем XFS (з Irix) і JFS (з AIX) відповідно.
Прикладне ПЗ
Засоби розробки додатків
Більшість засобів розробки для Linux сьогодні були створені в рамках проекту GNU. Вони містять у собі GCC - Gnu Compiler Colection - універсальний переносний компілятор, GDB - Gnu Debuger - відлагоджувач, GNU C Library та ін. Компілятор GCC створювався максимально переносним, завдяки чому він підтримує біля 100 різноманітних апаратних платформ. Мова опису платформи добре документована, завдяки чому перенос GCC на нову архітектуру не складає особливої проблеми. "Зверху" GCC являє собою компілятор мов С (KR C, ANSI C, C9x і власні розширення), C++ (ANSI C++, STL), Objective C, Fortran 77, Effiel. Останні версії GCC містять також компілятор мови Java у машинно залежні коди. Окремо від GCC поширюються компілятори Ada95 і Pascal, що використовують gcc для генерації коду. Для Linux також існують інтерпретатори Lisp, Scheme і інших Lisp-подібних мов, скриптових мов Perl, AWK, Shell, Sed та ін. Існують засоби підтримки ведення проекту і контролю версій (CVS), група пакетів, що полегшують написання переносних програм: autoconf, automake, libtool та ін., різноманітні IDE.Компанія IBM перенесла на Linux своє середовище розробки Java додатків - IBM VisualAge for Java на Linux. Inprise (Borland
ПЗ для серверів Internet/Intranet
Стандартно в постачання Linux входять: Apache - самим популярний у Internet http-сервер, Sendmail - програма передачі електронної пошти (Mail Transfer Agent), ftp, pop3/imap, news сервери, сервер доменових імен, uucp over tcpip, squid ( кешируючий http/ftp проксі), засоби динамічної маршрутизації та ін.
Файл сервер
Linux може служити файл сервером по протоколах NFS (як правило використовуваному тільки на Unix машинах), SMB (Netbios over TCP/IP, використовуваний на різноманітних Windows платформах), AppleShare і IPX (Novell).
Middleware
Існує декілька вільних реалізацій архітектури OMG CORBA.
Графічний інтерфейс
Linux використовує стандартну віконну систему X. У більшості дистрибутивів використовується вільно розповсюджувана реалізація X"ів XFree86. - підтримує (майже) усі популярні графічні адаптери на платформі Intel та деякі інші. Віконна система X побудована на клієнт-серверній архітектурі, у такий спосіб місце запуску додатка і місце його відображення можуть бути фізично рознесені по мережі. У останню (поки експериментальну) версію XFree86 - 4.0, входить підтримка OpenGL і апаратної 3D акселерації.
Засоби розробки під X, що входять у стандарт, подають тільки базовий API розробника. Як правило при розробці додатків використовують додаткові бібліотеки для побудови інтерфейсу. Набір інтегрованих базових додатків, побудованих на одній бібліотеці утворить графічне середовище користувача. Найбільше популярні графічні середовища сьогодні - Gnome (GNU Network Object Model Environment) і напівкомерційне середовище KDE.
СКБД
Основні виробники систем керування базами даних вже перенесли свої продукти на Linux: існують Linux версії IBM DB2, Informix, Oracle, Sybase, Corel/Inprise Interbase та ін. Linux може використовуватися в якості платформи для запуску системи керування підприємством SAP R/3.
Засоби підготування текстів
У дистрибутивах Linux звичайно поставляється TeTeX реалізація TeX - системи верстки текстів топографічної якості, створеної американським математиком і програмістом Дональдом Кнутом. Система TeX та макропакет високого рівня LaTeX сьогодні використовуються для публікації наукових статей, часописів і книг.
SGML Tools: засоби трансформації структурованого по правилах SGML тексту в LaTeX, HTML, GNU info, LyX, RTF, plain text і інші формати з одного вихідного тексту, орієнтовані на створення технічної документації.
Офісні пакети
Крім декількох проектів по створенню вільно розповсюджуваного комплекту офісних додатків для X"ів, під Linux існують комерційні офіси SUN Staroffice (сьогодні абсолютно безкоштовний для будь-якого застосування), Corel WordPerfect, Applix Applixware та деякі інші.
Ігри
Виробники комп"ютерних ігор вже звернули свою увагу на Linux. Вже вийшли Linux версії Doom, Doom2, Heretic, Descent, Quake, Quake II, Quake III test, Unreal, Myth II, Civilisation III Ctp та ін. С виходом XFree86 4.0, що містить крім всього іншого орієнтовану на ігри підсистему швидкої графіки і OpenGL, очікується збільшення числа ігор під Linux. Linux може служити сервером для ігор QuakeWorld, QuakeII, QuakeIII test, Unreal та ін.
Таблиця розрахунків PR і трохи про тИЦ
скільки потрібно мати посилань з сторінок PR ==> | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| щоб отримати PR своєї сторінки (без перелінкивки) не менше: ==> | 2 | 101 | 18 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
3 | 555 | 101 | 18 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | |
4 | 3055 | 555 | 101 | 18 | 3 | 1 | 1 | 1 | 1 | 1 | |
5 | 16803 | 3055 | 555 | 101 | 18 | 3 | 1 | 1 | 1 | 1 | |
6 | 92414 | 16803 | 3055 | 555 | 101 | 18 | 3 | 1 | 1 | 1 | |
7 | 0.5 млн. | 92414 | 16803 | 3055 | 555 | 101 | 18 | 3 | 1 | 1 | |
8 | 2.8 млн. | 0.5 млн. | 92414 | 16803 | 3055 | 555 | 101 | 18 | 3 | 1 | |
9 | 15 млн. | 2.8 млн. | 0.5 млн. | 92414 | 16803 | 3055 | 555 | 101 | 18 | 3 | |
10 | 84 млн. | 15 миллионов | 2.8 млн. | 0.5 млн. | 92414 | 16803 | 3055 | 555 | 100 | 18 | |
А тепер щодо тИЦ, ТИЦ - з слів яши це індекс цитування (Индекс цитирования). При вимірюванні тиця беруться тільки ті сайти, які проіндексовані і занесені в каталоги яндекса. Силки з блогів, форумів, дошок оголошень і тепер уже з каталогів в які кожний може залишити свою ссилочку яша взагалі невраховує. Тиц яші присвоюється не певним сторінкам, як це робить гугля, а всьому домену. Також варто зазначити, що ссилки з сайтів, які зенесені в яндекс каталог - дом и семь мало що будуть значити для нашого сайта про автомобілі, в цьому і вся сіль тИЦ. Потрібно щоб тицьовий сайт, який посилається на нас був в томуж яндекс каталозі що і наш, відповідав нашй темі. Точо ніхто не може сказати скільки потрібно посилань для отримання сайтом тИЦ 10. Їх можу бути 100, а може 1000, а тиц 10 так і не отримати.
Trackback URL для цього допису
http://my3ukablog.com.ua/trackback/152
c++0x: std::thread
В c++0x зявилося багато нових можливостей одна з них багатопоточність, дуже проста в використанні.
//thread.cpp
#include <iostream>
#include <thread>
void func() {
std::cout<<"hello\n";
}
void func2() {
std::cout<<"hello2";
}
int main (int argc, char const* argv[]) {
std::thread t(func);
std::thread t2(func2);
t.join();
t2.join();
return 0;
}
Для компіляції потрібен gcc 4.3: g++ -Wall -std=c++0x -o thread thread.cpp.
Опція -std=c++0x дає компілятору вказівку компілювати код як c++0x, ане c++03.
Клас std::string
C++ Standard Template Library (STL) містить рядок, клас, який використовується в декількох класах інформатики. Для того щоб використовувати клас рядків ви повинні включити наступні твердження:
#include <string>
using std::string;
наступні рядки зазначають початкові змінні:
string s = "abc def abc"
string s2 = "abcde uvwxyz"
char c;
char ch[] = "aba daba do"
char *cp = ch;
unsigned int i;
#include <string>
using std::string;
наступні рядки зазначають початкові змінні:
string s = "abc def abc"
string s2 = "abcde uvwxyz"
char c;
char ch[] = "aba daba do"
char *cp = ch;
unsigned int i;
Stream input | cin >> s; | Changes the value of s to the value read in. The value stops at whitespace. |
Stream output | cout << s; | Writes the string to the specified output stream. |
Line input | getline(cin, s); | Reads everything up to the next newline character and puts the result into the specified string variable. |
Assignment | s = s2;s = "abc"; s = ch; s = cp; | A string literal or a string variable or a character array can be assigned to a string variable. The last two assignments have the same effect. |
Subscript | s[1] = 'c'; c = s[1]; | Changes s to equal "acc def abc" Sets c to 'b'. The subscript operator returns a char value, not a string value. |
Length | i = s.length(); i = s.size(); | Either example sets i to the current length of the string s |
Empty? | if(s.empty()) i++; if(s == "") i++; | Both examples add 1 to i if string s is now empty |
Relational operators | if (s < s2) i++; | Uses ASCII code to determine which string is smaller. Here the condition is true because a space comes before letter d |
Concatenation | s2 = s2 + "x"; s2 += "x"; | Both examples add x to the end of s2 |
Substring | s = s2.substr(1,4); s = s2.substr(1,50); | The first example starts in position 1 of s2 and takes 4 characters, setting s to "bcde". In the second example, s is set to "bcde uvwxyz". If the length specified is longer than the remaining number of characters, the rest of the string is used. The first position in a string is position 0. |
Substring replace | s.replace(4,3,"x"); | Replaces the three characters of s beginning in position 4 with the character x. Variable s is set to "abc x abc". |
Substring removal | s.erase(4,5); s.erase(4); | Removes the five characters starting in position 4 of s. The new value of s is "abc bc". Remove from position 4 to end of string. The new value of s is "abc ". |
Character array to string | s = ch; | Converts character array ch into string s. |
String to character array | cp = s.c_str(); | Pointer cp points to a character array with the same characters as s. |
Pattern matching | i = s.find("ab",4); if(s.rfind("ab",4) != string::npos) cout << "Yes" << endl; | The first example returns the position of the substring "ab" starting the search in position 4. Sets i to 8. The find and rfind functions return the unsigned int string::npos if substring not found. The second example searches from right to left starting at position 4. Since the substring is found, the word Yes is printed. |
Як облаштувати сирцевий код шаблона
Введення
Часто мене запитували складно чи лекго програмувати з шаблонами. Відповідь яку я зазвичай давав така: “Це легко коли ти використовуєш, але складно коли створюєш їх”. Лиш погляньте на деякі бібліотеки шаблонів, які використовуються повсякденно, наприклад, STL, ATL, WTL, деякі бібліотеки з Boost, і ви побачите, що я маю на увазі під цим. Ці бібліотеки є чудовим прикладом принципу “простий інтерфейс – складна реалізація”.
Я почав використовувати шаблони п’ять років тому, коли я виявив шаблонні контейнери MFC, і до минулого року я не мав потреби в розробці власних шаблонів. Коли я кінцево дійшов висновку, що я потребую розробки деяких власних класів шаблонів, перше, що вразило мене був той факт, що “традиційний” шлях облаштування сирцевого коду (об’явлення в *.h файлах, і визначення в *.cpp файлах) не працює з шаблонами. Це зайняло в мене трохи часу, щоб зрозуміти в чому річ і знайти як обійти цю проблему.
Ця стаття спрямована на розробників, які достатньо добре знаються на шаблонах, щоб використовувати їх, але недостатньо досвідчені для розробки. Тут, я зачеплю лиш класи шаблони, а не функції шаблони, але принципи однакові в обох випадках.
Тепер, що станеться якщо ми спробуємо організувати код більш традиційним чином? Давайте спробуймо виділити код в array.h і подивитись, що вийде. Зараз ми маємо два файли: array.h і array.cpp (main.cpp залишається незмінним).
Постають такі питання:
Точка інстанціонування розташована в файлі main.cpp. Якщо ми облаштовуємо код за звичайним підходом, компілятор бачить об’явлення шаблона (array.h), але не визначення (array.cpp). Тож, компілятор буде нездатен створити тип array<int, 50>.
Однак, він е прозвітує про помилку: він вважтиме, що цей тип визначений в якійсь іншій одиниці компіляції і полишить це на компонувальник.
Тепер, що станеться з іншою одиницею компіляції (array.cpp)? Компілятор розбере визначення шаблона і перевірить синтакс на вірність, але не сгенерує код для функцій членів. Чому так? Для створення коду, компілятор має знати параматри шаблона – він потребує тип, а не шаблон.
Тож, компоновник не знайде визначення для array<int, 50> ані в main.cpp ані в array.cpp, звідси і виникають помилки про незнайдені визначення членів.
Добре. Це відповідь на питання 1. Але що з питанням 2? Ми маємо чотири функції члена визначені в array.cpp, і тільки три повідомлення про помилки видані компонувальником. Питання знаходиться в концепції лінивого інстанціонування. В main.cpp ми не використовуємо operator[] і компілятор навіть не намагався інстанціонувати це визначення.
Перше рішення значить, що ми маємо включити не тільки об’явлення шаблона, але й визначення до кожної одиниці трансляції в якій ми використовуємо шаблони. В нашому випадку це означає, що ми будемо використовувати першу версію array.h з усіма вбудованими функціями членами, або ми включимо array.cpp в наш main.cpp. В цьому випадку, компілятор бачитиме і об’явлення, і визначення всіх функцій членів з array і буде здатен інстанціонувати array<int, 50>. Недоліком цього підходу є те, що наші одиниці компіляції можуть стати великими, і це значно збільшить час компіляції і компонування.
Зараз друге рішення. Ми можемо явно інстанціонувати шаблон для типів, які потребуємо. Найкраще тримати всі явні вказівки інстанціації в окремомій одиниці компіляції. Тут ми можемо додати новий файл templateinstantiations.cpp
Третє рішення полягає в позначенні визначень шаблона ключовим словом export і компілятор потурбується про інше. Коли я читав про export у книзі Страуструпа, я був сповненим натхнення стосовно цієї директиви.
Це зайняло у мене декілька хвилин, щоб віднайти, що вони нереалізована в VC 6.0, і трошки більше, щоб знайти, не існує компілятора з підтримкою цього ключового слова (перший компілятор з такою підтримкою вийшов у 2002). Відтоді, я багато прочитав про export і вивчив, що вона заледве може вирішити будь-які проблеми пов’язані із моделлю включення.
Вихідна стаття
Часто мене запитували складно чи лекго програмувати з шаблонами. Відповідь яку я зазвичай давав така: “Це легко коли ти використовуєш, але складно коли створюєш їх”. Лиш погляньте на деякі бібліотеки шаблонів, які використовуються повсякденно, наприклад, STL, ATL, WTL, деякі бібліотеки з Boost, і ви побачите, що я маю на увазі під цим. Ці бібліотеки є чудовим прикладом принципу “простий інтерфейс – складна реалізація”.
Я почав використовувати шаблони п’ять років тому, коли я виявив шаблонні контейнери MFC, і до минулого року я не мав потреби в розробці власних шаблонів. Коли я кінцево дійшов висновку, що я потребую розробки деяких власних класів шаблонів, перше, що вразило мене був той факт, що “традиційний” шлях облаштування сирцевого коду (об’явлення в *.h файлах, і визначення в *.cpp файлах) не працює з шаблонами. Це зайняло в мене трохи часу, щоб зрозуміти в чому річ і знайти як обійти цю проблему.
Ця стаття спрямована на розробників, які достатньо добре знаються на шаблонах, щоб використовувати їх, але недостатньо досвідчені для розробки. Тут, я зачеплю лиш класи шаблони, а не функції шаблони, але принципи однакові в обох випадках.
Опис проблеми
Щоб показати проблему розглянемо приклад. Припустимо ми маємо клас шаблонarray у файлі array.h.// array.h template <typename T, int SIZE> class array { T data_[SIZE]; array (const array& other); const array& operator = (const array& other); public: array(){}; T& operator[](int i) {return data_[i];} const T& get_elem (int i) const {return data_[i];} void set_elem(int i, const T& value) {data_[i] = value;} operator T*() {return data_;} };Також ми маємо файл main.cpp з кодом, що використовує масив:
// main.cpp #include "array.h" int main(void) { array<int, 50> intArray; intArray.set_elem(0, 2); int firstElem = intArray.get_elem(0); int* begin = intArray; }Це компілюється добре і робить саме те, що ми хочемо: спочатку ми створюємо масив 50 цілих, далі присвоюємо першому елементові 2, читаємо цей елемент і зрештою отримуємо вказівник на початок масиву.
Тепер, що станеться якщо ми спробуємо організувати код більш традиційним чином? Давайте спробуймо виділити код в array.h і подивитись, що вийде. Зараз ми маємо два файли: array.h і array.cpp (main.cpp залишається незмінним).
// array.h template <typename T, int SIZE> class array { T data_[SIZE]; array (const array& other); const array& operator = (const array& other); public: array(){}; T& operator[](int i); const T& get_elem (int i) const; void set_elem(int i, const T& value); operator T*(); };
// array.cpp #include "array.h" template<typename T, int SIZE> T& array<T, SIZE>::operator [](int i) { return data_[i]; } template<typename T, int SIZE> const T& array<T, SIZE>::get_elem(int i) const { return data_[i]; } template<typename T, int SIZE> void array<T, SIZE>::set_elem(int i, const T& value) { data_[i] = value; } template<typename T, int SIZE> array<T, SIZE>::operator T*() { return data_; }Спробуйте скомпілювати це, і ви отримаєте три помилки компонувальника.
Постають такі питання:
- Чому взагалі з’явились ці помилки?
- Чом лише три помилки? Миж маємо чотири функції члена в array.cpp.
Інстанціонування шаблонів
Одніює зі звичайних помилок програмістів є те, що коли вони працюють з класами шаблонами вони розглядають ці класи як типи. Певно термін параметризовані типи, який часто використовується для класів шаблонів, призводить до подібного мислення. Добре, класи шаблони це не типи, вони лише те, що говорить їх ім’я: шаблони. Існує декілька важливих концепцій для розуміння стосунків між класами шаблонами і типами:- Компілятор використовує класи шаблони для створення типів шляхом заміни параметрів шаблона,
і цей процес зветься інстанціюванням. - Тип створений з класу шаблона зветься спеціалізацією.
- Інстанціонування шаблона відбувається за запитом, це означає, що компілятор створює спеціалізацію тоді, коли знаходить її викоритсання в коді
(це місце зветься точкою інстанціонування). - Для створення спеціалізації компілятор в точці інстанціонування має “бачити” не тільки
об’явлення шаблона, але також визначення. - Інстанціонування шаблона ліниве, це значить, що інстанціонуються лиш функції, що використовуються.
Точка інстанціонування розташована в файлі main.cpp. Якщо ми облаштовуємо код за звичайним підходом, компілятор бачить об’явлення шаблона (array.h), але не визначення (array.cpp). Тож, компілятор буде нездатен створити тип array<int, 50>.
Однак, він е прозвітує про помилку: він вважтиме, що цей тип визначений в якійсь іншій одиниці компіляції і полишить це на компонувальник.
Тепер, що станеться з іншою одиницею компіляції (array.cpp)? Компілятор розбере визначення шаблона і перевірить синтакс на вірність, але не сгенерує код для функцій членів. Чому так? Для створення коду, компілятор має знати параматри шаблона – він потребує тип, а не шаблон.
Тож, компоновник не знайде визначення для array<int, 50> ані в main.cpp ані в array.cpp, звідси і виникають помилки про незнайдені визначення членів.
Добре. Це відповідь на питання 1. Але що з питанням 2? Ми маємо чотири функції члена визначені в array.cpp, і тільки три повідомлення про помилки видані компонувальником. Питання знаходиться в концепції лінивого інстанціонування. В main.cpp ми не використовуємо operator[] і компілятор навіть не намагався інстанціонувати це визначення.
Розв’язки
Тепер, коли ми розуміємо звідки витікає проблема, було б добре запропонувати якісь шляхи її ров’язання. Ось вони:- Зробити визначення шаблона видимим в точці інстанціонування.
- Інстанціонувати необхідні типи в окремій одиниці компіляції, так щоб компонувальник міг їх знайти.
- Використати ключове слово export.
Перше рішення значить, що ми маємо включити не тільки об’явлення шаблона, але й визначення до кожної одиниці трансляції в якій ми використовуємо шаблони. В нашому випадку це означає, що ми будемо використовувати першу версію array.h з усіма вбудованими функціями членами, або ми включимо array.cpp в наш main.cpp. В цьому випадку, компілятор бачитиме і об’явлення, і визначення всіх функцій членів з array і буде здатен інстанціонувати array<int, 50>. Недоліком цього підходу є те, що наші одиниці компіляції можуть стати великими, і це значно збільшить час компіляції і компонування.
Зараз друге рішення. Ми можемо явно інстанціонувати шаблон для типів, які потребуємо. Найкраще тримати всі явні вказівки інстанціації в окремомій одиниці компіляції. Тут ми можемо додати новий файл templateinstantiations.cpp
// templateinstantiations.cpp #include "array.cpp" template class array <int, 50>; // explicit instantiationТип array<int, 50> буде сгенеровано не в main.cpp але в templateinstantiations.cpp і компонувальник знайде визначення. В цьому піході ми уникаємо великих заголовкових файлів, і звідси час збирання зменшується. Також, заголовкові файли будуть “чистими” і більш читабельними. Однак, тут ми не маємо переваги лінивого інстанціонування (явне інстанціонування генерує код для всіх функцій членів), і це може стати складно підтримувати templateinstantiations.cpp для великих проектів.
Третє рішення полягає в позначенні визначень шаблона ключовим словом export і компілятор потурбується про інше. Коли я читав про export у книзі Страуструпа, я був сповненим натхнення стосовно цієї директиви.
Це зайняло у мене декілька хвилин, щоб віднайти, що вони нереалізована в VC 6.0, і трошки більше, щоб знайти, не існує компілятора з підтримкою цього ключового слова (перший компілятор з такою підтримкою вийшов у 2002). Відтоді, я багато прочитав про export і вивчив, що вона заледве може вирішити будь-які проблеми пов’язані із моделлю включення.
Висновок
При розробці бібліотек шаблонів, ми маємо розуміти, що класи шаблонів це не “звичайні типи” і, що ми маємо мислити інакше під час роботи з ними. Метою цієї статті було не злякати розробників, які бажають програмувати шаблони. Навпаки, я сподіваюсь, що це допоможе їм уникнути розповсюджених помилок, яких припускаються люди, які щойно приступили до розробки шаблонів.Вихідна стаття
Вступ у використання рекурсії в C++
1. Вступ
Загалом, рекурсія значить самоповторюваний шаблон. В математиці це може бути функція визначена через себе. Інакше кажучи, це функція, що викликає сама себе. Кожна рекурсивна функція має умову завершення; інакше вона буде викликати себе безперестанку, і ця умова може бути названою базова умова.Зазвичай, рекурсія це трошки складна для розуміння більшості студентів концепція.
2. Типи рекурсії
В C++, типи рекурсії можна визначити більш ніж за одним виміром. З одного боку, їх можна категоризувати як рекурсії часц виконання і як рекурсії часу компіляції через використання шаблонів. Рекурсії часу вионання найбільш уживана техніка в С++. Вона може бути здійснена через функції (функції члени), які викликають самі себе.В C++, ми також можемо реалізувати рекурсії часу компіляції за допомогою шаблонів. Коли ви інстанціюєте класс (або структуру) шаблон в С++, компілятор створиює код цього класу під час компіляції. Як і рекурсії часу виконання, клас шаблон може інстанціонувати себе самого для забезпечення рекурсії. Так само потрібна умова завершення; інакше інстанціонування триватиме безупинно, щонайменше теоретично, хоча звісно в дійсності цей процес обмежений ресурсами комп’ютера і компілятора. В такому шаблоні, ви можете визначити умову завершення (базову умову) за допомогою спеціалізації шаблона або часткової спеціалізації, залежно від умови завершення.
Дехто може подумати, що він зможе реалізувати рекурсію за допомогою макросов препроцесора С++, бо вони теж заміняються під час компіляції. Насправді, препроцесор заміняє макроси ще перед компіляцією. Також препроцесор має багато обмежень; через просту заміну тексту, тут немає визначення символу зневадження для зневаджувача, але найбільш критичне обмеження те, що макроси не можуть викликати себе рекурсивно; тож ви не можете програмували рекурсії за допомогою макросів, накшталт мета-програмуванню.
Інший погляд на рекурсію це погляд на те як реалізован алгоритм рекурсії. Алгоритм рекурсії може бути реалізовним більш ніж одним способом. Можливі варіанти рекурсії це лінійна, хвостова, обопільна, двійкова і вкладена. Ви можете здійснити їх або під час компіляції через використання шаблонів або під час виконання через використання функцій або функцій членів.
Наступна діаграма показує різні типи рекурсії в залежності від їх реалізації.

Зараз ви зможете дослідити різні типи алгоритмів один за одним і побачити їх реалізації часу виконання і часу компіляції.
3. Лінійна рекурсія
Лінійна рекурсія це найпростіший вид рекурсії і можливо найбільш вживана рекурсія. В цій рекурсії, одна функція просто викликає себе доти, доки не досягне умови завершення (також відомої як базова умова); цей процес відомий як намотування. Як тільки виконана умова завершення, виконання програми повертається до викликальника; це зветься розмотуванням.Впродовж намотування і розмотування функція може виконувати якісь додаткові корисні задачі; у випадку факторіала вона множить вхідне значення на значення повернуте під час фази розмотування. Цей процес може бути зображений у вигляді наступної діаграми (знизу), яка показує обидві фази функції обчислення факторіала із використанням лінійної рекурсії.

Математично, ви можете написати функцію обчислення факторіала таким чином; інакше кажучи, коли значення “n” нуль, повертати одинцю і, коли значення “n” більше ніж нуль, викликати функцію рекурсивно з “n-1″ і помножити результат на “n”.
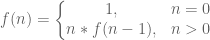
int Factorial(int no) { // перевірка на помилковий параметр if (no < 0) return -1; // умова завершення if (0 == no) return 1; // лінійний рекурсивний виклик return no * Factorial(no - 1); }Програма 1: Приклад лінійної рекурсії часу виконання
Попередня програма являє собою реалізацію лінійної рекурсії часу виконання. Тут ми маємо умову завершення у вигляді 0; програма починає виконувати розмотування коли досягає умови завершення. В цій програмі присутня перевірка на введення від’ємного числа, яке могло б спричините нескінченну рекурсію. Ця функція просто поверне -1 як помилку якщо параметр від’ємний.
template <int No> struct Factorial{ // лінійний рекурсивний виклик enum { value = No * Factorial<No - 1>::value }; }; // умова завершення template <> struct Factorial<0> { enum { value = 1 }; };Програма 2: Приклад лінійної рекурсії часу компіляції
Ця програма є прикладом лінійної рекурсії під час компіляції. Тут ми використовуємо інстанціонування шаблона для здійснення рекурсії. Також ми маємо умову завершення у вигляді спеціалізації шаблона. Це дуже простий приклад спеціалізації шаблонів і в ньому немає багато коду, але в деяких випадках вам доведеться переписати весь код у спеціалізації класу (або структури) шаблона, бо ви не можете успадкувати код з класу (або структури) шаблона для його спеціалізації.
Тут навіть не треба вводити перевірку на помилкове введення, бо програма просто не скомпілюється, якщо хтось спробує подати від’ємне число. Це дуже велика перевага рекурсії часу компіляції, що ви навіть не зможете скомпілювати нескінченну рекурсію. Однак, повідомлення про помилку може бути не зовсім зрозумілим.
Приклади використання рекурсії часу компіляції.
cout << Factorial::value << endl; cout << Factorial::value << endl; cout << Factorial::value << endl;Компілятор відмовиться скомпілювати останнє ствердження і видасть довге повідомлення про помилку.
4. Хвостова рекурсія
Хвостова рекурсія це спеціальна форма лінійної рекурсії, де рекурсивний виклик зазвичай іде останнім у функції. Цей тип рекурсії здебільшого більш ефективний, бо розумні компілятори автоматично перетворять таку рекурсію в цикл задля уникнення вкладених викликів функцій. Через те, що рекурсивний виклик функції зазвичай останнє, що робить функція, вона не має потреби ще щось робити під час розмотування; натомість, вона просто повертає значення отримане через рекурсивний виклик. Ось приклад тої самої програми реалізованої як хвостова рекурсія.
Ви можете визначити хвостову рекурсію математично через наступну формулу; інакше кажучи, коли значення “n” нуль, просто повернути значення “a”; якщо значення “n” більше ніж нуль, викликати рекурсивну функцію з параметрами “n-1″ і “n*a”. Також, можна зауважити, що під час фази розмотування кожна рекурсивно викликана функція просто просто повертає значення “a”.

int Factorial(int no, int a) { // перевірка на помилковий параметр if (no < 0) return -1; // умова завершення if (0 == no || 1 == no) return a; // хвостовий рекурсивний виклик return Factorial(no - 1, no * a); }Програма 3: Приклад хвостової рекурсії часу виконання
Це змінена версія програми з лінійною рекурсією. Ви виконуєте всі обчислення до виклику рекурсивної функції, і просто повертаєте значення отримане з цього виклику. Тут, порядок обчислення зворотній до порядку за лінійної рекурсії. У випадку лінійної рекурсії, ви спочатку множите 1 на 2; отриманий результат на 3 і так далі. З іншого боку, тут ви множите n на n-1, і тоді на n-2 доки не досягнете 0.
template <int No, int a> struct Factorial{ // хвостовий рекурсивний виклик enum { value = Factorial<No - 1, No * a>::value }; }; // умова завершення template <int a> struct Factorial<0, a> { enum { value = a }; };Програма 4: Приклад хвостової рекурсії часу компіляції
Ось версія рекурсії часу компіляції тої самої програми, вона виконує те саме під час компіляції.
Хвостова рекурсія дуже корисна і часом неуникна в функціональниї мовах програмування, бо деякі з них можуть не підтримувати циклічні конструкції. Тоді, зазвичай, цикли реалізуються за допомогою хвостової рекурсії. За допомогою хвостової рекурсії ви можете робити майже все, що можна зробити з циклом, але в зворотньому напрямку це часто не вірно. От дуже простий приклад, що демонструє цикл через хвостову рекурсію.
// реалізація циклу через хвостову рекурсію // проста версія void RecursiveLoop(int n) { // умова завершення if (0 == n) return; // дія cout << n << endl; // хвостовий рекурсивний виклик return RecursiveLoop(--n); }Програма 5: Демонстрація реалізації циклу через хвостову рекурсію, проста версія
Але ця програма виглядає дуже жорсткою і ви не можете налаштувати її. Ось змінений варіант цієї програми, в якому за допомогою шаблонів і функціональних об’єктів, ви зможете налаштовувати програму під свої потреби.
// реалізація циклу через хвостову рекурсію // шаблонна версія template <typename TType, typename TTerminate, typename TAction, typename TStep> void RecursiveLoop(TType n) { // умова завершення if (TTerminate()(n)) return; // дія TAction()(n); // хвостовий рекурсивний виклик return RecursiveLoop<TType, TTerminate, TAction, TStep>(TStep()(n)); }Програма 6: Демонстрація реалізації циклу через хвостову рекурсію, шаблонна версія
Ось реалізації “Умови завершення”, “Дії”, та “Крокування циклом”.
// умова завершення визначена користувачем template <typename T> class IsTerminate{ public: // оператори визначені в цій функції // мають бути перевантаженими для даного типу T bool operator () (T n) { return n == 0 ? true : false; } }; // умова переходу на наступний крок визначена користувачем template <typename T> class Step{ public: // оператори визначені в цій функції // мають бути перевантаженими для даного типу T T operator () (T n) { return --n; } }; // дія визначена користувачем template <typename T> class Action{ public: // оператори визначені в цій функції // мають бути перевантаженими для даного типу T void operator () (T n) { cout << n << endl; } };Програма 6: Реалізація кожного кроку для рекурсивного циклу через шаблонну версію хвостовою рекурсії.
Ось простий приклад використання цієї функції.
// реалізація циклу через хвостову рекурсію // шаблонна версія RecursiveLoop, Action, Step >(10);Ви не можете надати реалізацію за умовчанням у функції “RecursiveLoop”, бо С++ не дозволяє параметр за замовчанням для шаблонів функцій. Ви можете робити це тільки у випадку класів С++. З метою подолання цього обмеження ви можете використати функціональні об’єкти замість простих функцій і передати дію за замовчанням як параметр за замовченням, тож виклик буде значно простіший. Подаємо переглянуту версію цієї програми.
template <typename TType, typename TTerminate = IsTerminate<TType>, typename TAction = Action<TType>, typename TStep = Step<TType> > class RecursiveLoop{ public: void operator ()(TType n) { // умова завершення if (TTerminate()(n)) return; // дія TAction()(n); // хвостовий рекурсивний виклик return RecursiveLoop<TType, TTerminate, TAction, TStep>()(TStep()(n)); } };Програма 7: Реалізація циклу через хвостову рекурсію із використанням функціональних об’єктів і параметра шаблона за замовчанням.
Відтак, використання цього функціонального об’єкта дуже просте.
RecursiveLoop()(10);5. Обопільна рекурсія
Обопільна рекурсія також відома як непряма рекурсія. В цьому типі рекурсії, дві або більше функції викликають одна одну циклічно. Це єдиний шлях для здійснення рекурсії в мовах, що не дозволяють вам викликати функції рекурсивно. Умова завершення в такій рекурсії може знаходитись в одній або всіх функціях.

Математично, ви можете визначити ці функції як


bool isEven(int no) { // умова завершення if (0 == no) return true; else // взаємний рекурсивний виклик return isOdd(no - 1); } bool isOdd(int no) { // умова завершення if (0 == no) return false; else // взаємний рекурсивний виклик return isEven(no - 1); }Програма 8: Приклад обопільної рекурсії часу виконання
Це дуже примітивний приклад обопільної рекурсії. Ви знаєте, що нуль це парне число, одиниця непарне. Якщо ви хочете дізнатися чи парне число, ви можете використати ці функції; на внутрішньому рівні вони викликають одна одну і віднімають одиницю з вхідного значення доки не досягнуть виконання базової умови. Звісно, це не найліпший шлях для реалізації цього алгоритму; тут потрібна велика кількість ресурсів для визначення чи число парне. Крім того, якщо передати від’ємне число, функції будуть викликати одна одну доки не відбудеться переповнення стека.
template <int no> struct isEven{ // взаємний рекурсивний виклик enum { value = no == 0 ? 1 : isOdd<no - 1>::value }; }; // умова завершення template <> struct isEven<0> { enum { value = 1 }; }; template <int no> struct isOdd{ // взаємний рекурсивний виклик enum { value = no == 0 ? 0 : isEven<no - 1>::value }; }; // умова завершення template <> struct isOdd<0> { enum { value = 0 }; };Програма 9: Приклад обопільної рекурсії часу компіляції
Ось версія програми із рекурсією часу компіляції. Єдина відмінність між програмами полягає в тому, що приклад часу компіляції навіть не скомпілюється за умови передачі від’ємного числа.
Визначення парності числа за допомогою обопільної рекурсії не дуже добра ідея. Більш цікавим прикладом є чоловіча і жіноча послідовності. Обидві функції рекурсивно викликають одна одну і можуть представлені так.

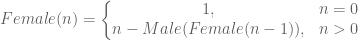
Наведемо приклади часу виконання і часу компіляції чоловічої і жіночої функцій із використанням обопільної рекурсії.
int MaleSequence(int n) { // умова завершення if (0 == n) return 0; // взаємний рекурсивний виклик return n - FemaleSequence(MaleSequence(n-1)); } int FemaleSequence(int n) { // умова завершення if (0 == n) return 1; // взаємний рекурсивний виклик return n - MaleSequence(FemaleSequence(n-1)); }Програма 10: Реалізація часу виконання Male і Female функцій,.
template <int n> struct MaleSequence{ // взаємний рекурсивний виклик enum { value = n - FemaleSequence<MaleSequence<n - 1> ::value>::value }; }; // умова завершення template <> struct MaleSequence<0> { enum { value = 0 }; }; template <int n> struct FemaleSequence{ // взаємний рекурсивний виклик enum { value = n - MaleSequence<FemaleSequence<n - 1> ::value>::value }; }; // умова завершення template <> struct FemaleSequence<0> { enum { value = 1 }; };Як і з іншими функціями часу виконання, ви маєте зробити спеціалізацію шаблона для обох функцій з метою опрацювання умови завершення.
6. Двійкова рекурсія
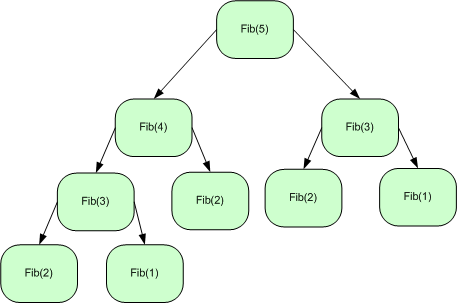
У випадку двійкової рекурсії функція викликає себе двічі, замість одного разу. Такий тип рекурсії дуже корисний при роботі з деякими структурами даних, наприклад при обході дерева в прямому, зворотньому або центрованому порядку або генерації чисел Фібоначчі і так далі.
Двійкова рекурсія це особлива форма експонентної рекурсії, де одна функція викликає себе більш ніж один раз (у випадку двійкової рекурсій).
Математично ви можете визначити послідовність Фібоначчі як
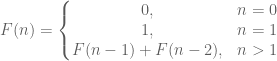
int Fib(int no) { // перевірка на помилковий параметр if (no < 1) return -1; // умова завершення if (1 == no || 2 == no) return 1; // подвійний рекурсивний виклик return Fib(no - 1) + Fib(no - 2); }Програма 12: Приклад часу виконання двійкової рекурсії
Ось проста реалізація послідовності Фібоначчі, що викликає рекурсивну функцію двічі. Тут ми маємо два базові випадкі; коли значення параметру на вході є 1 чи 2. Це, звісно, не найкраща реалізація послідовності Фібоначчі і ви можете перетворити її в хвостову рекурсію трошки змівнив її. Але, перед перетворенням її в хвостову рекурсію, погляньте на версію часу компіляції двійкової рекурсії.
template <int n> struct Fib{ // подвійний рекурсивний виклик enum { value = Fib<n - 1>::value + Fib<n - 2>::value }; }; // умова завершення template<> struct Fib<2> { enum { value = 1 }; }; // умова завершення template <> struct Fib<1> { enum { value = 1 }; };Програма 13: Приклад часу компіляції двійкової рекурсії
У версії часу компіляції двійкової рекурсії, ви двічі спеціалізуєте клас шаблон (або структуру). Загалом, ви маєте робити спеціалізацію шаблона для кожного базового випадку.
int Fib(int n, int a = 0, int b = 1) { // умова завершення if (1 == n) return b; else // хвостовий рекурсивний виклик return Fib(n-1, b, a+b); }Програма 14: Приклад часу виконання перетворення двійкової рекурсії в хвостову
Тут ви перетворюєте двійкову рекурсію в хвостову. Ви просто робите обчислення перед рекурсивним викликом; звідси, ви не маєте двічі робити рекурсивний виклик.
Математично це можна виразити як

template <int n, int a = 0, int b = 1> struct Fib{ // хвостовий рекурсивний виклик enum { value = Fib<n-1, b, (a+b)>::value }; }; // умова завершення template<int a, int b> struct Fib<1, a, b> { enum { value = b }; };Програма 15: Приклад часу компіляції перетворення двійкової рекурсії в хвостову
У версії часу компіляції ми маємо лише одну умову завершення (базову умову); тож ми потребуємо лише одну спеціалізацію шаблона. Тут робиться часткова спеціалізація, бо нас цікавить останнє обчислене значення в базовому випадку, коли n дорівнює 1.
7. Вкладена рекурсія
Це особливий тип рекурсії, коли рекурсивні виклики вкладені. В усіх попередніх типах рекурсії, ви можете замінити рекурсію на простий цикл або цикл зі стеком, але цей тип рекурсії не може бути легко замінений на простий цикл.
Типовим прикладом вкладеної рекурсії є функція Акермана.
Математично функція Акермана може бути визначена як
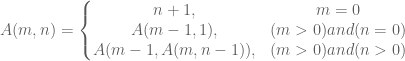
int Ackermann(int m, int n) { // перевірка параметрів if (m < 0 || n < 0) return -1; // умова завершення if (0 == m) return n + 1; // лінійний рекурсивний виклик else if (m > 0 && 0 == n) return Ackermann(m-1, 1); // вкладений рекурсивний виклик else return Ackermann(m-1, Ackermann(m, n-1)); }Програма 16: Приклад вкладеної рекурсії часу виконання
Ця функція має дві умови завершення;; одна умова припиняє вкладені виклики і починає лінійну рекурсію; друга умова завершення припиняє лінійну рекурсію. На початку розташована перевірка на допустимість параметрів.
template <int m, int n> struct Ackermann{ // вкладений рекурсивний виклик enum { value = Ackermann<m-1, Ackermann<m, n-1> ::value>::value }; }; template <int m> struct Ackermann<m, 0> { // лінійний рекурсивний виклик enum { value = Ackermann<m-1, 1>::value }; }; // умова завершення template <int n> struct Ackermann<0, n> { enum { value = n + 1 }; };Програма 17: Приклад вкладеної рекурсії часу компіляції
У випадку програми часу компіляції ви маєте реалізувати дві спеціалізації шаблонів через наявність двох умов завершення. Перша спеціалізація зупиняє вкладені виклики і починає лінійну рекурсію; друга зупиняє лінійну рекурсію.
Вихідна стаття
Підписатися на:
Дописи (Atom)